Big improvements in power and performance stem from low-level intelligence.

AI is being embedded into an increasing number of technologies that are commonly found inside most chips, and initial results show dramatic improvements in both power and performance.
Unlike high-profile AI implementations, such as self-driving cars or natural language processing, much of this work flies well under the radar for most people. It generally takes the path of least disruption, building on or improving technology that already exists. But in addition to having a significant impact, these developments provide design teams with a baseline for understanding what AI can and cannot do well, how it behaves over time and under different environmental and operating conditions, and how it interacts with other systems.
Until recently, the bulk of AI/machine learning has been confined to the data center or specialized mil/aero applications. It has since begun migrating to the edge, which itself is just beginning to take form, driven by a rising volume of data and the need to process that data closer to the source.
Memory improvements
Optimizing the movement of data is an obvious target across all of these markets. So much data is being generated that it is overwhelming traditional von Neumann approaches. Rather than scrap proven architectures, companies are looking at ways to reduce the flow of data back and forth between memories and processors. In-memory and near-memory compute are two such solutions that have gained attention, but adding AI into those approaches can have a significant incremental impact.
Samsung’s announcement that it is adding machine learning into the high-bandwidth memory (HBM) stack is a case in point.
“The most difficult part was how to make this as a drop-in replacement for existing DRAM without impacting any of the computing ecosystem,” said Nam Sung Kim, senior vice president of Samsung’s Memory Business Unit. “We still use existing machine learning algorithms, but this technology is about running them more efficiently. Sometimes it wasn’t feasible to run the machine learning model in the past because it required too much memory bandwidth. But with the computing unit inside the memory, now we can explore a lot more bandwidth.”
Kim said this approach allowed a 70% reduction in total system energy without any additional optimization. What makes this so valuable is that it adds a level of “intelligence” into how data is moved. That, in turn, can be paired with other technology improvements to achieve even greater power/performance efficiency. Kim estimates this can be an order of magnitude, but other technologies could push this even higher.
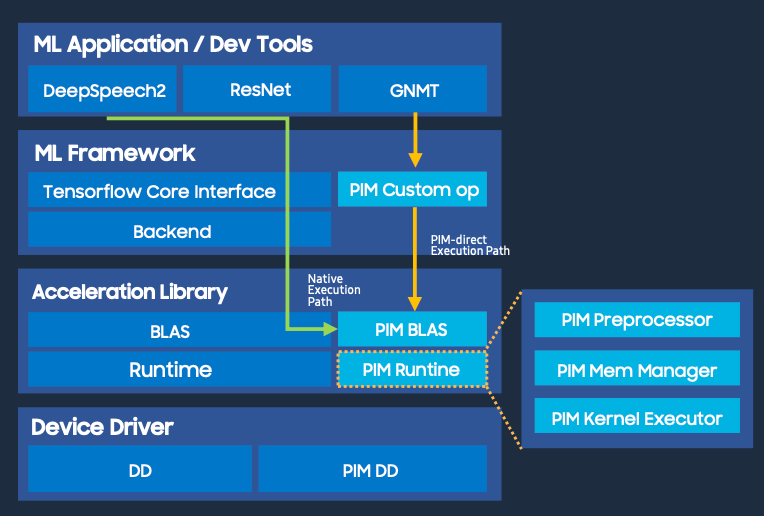
Fig. 1: Processing in memory software stack. Source: Samsung
“As an industry, we have to look in a few different places,” said Steven Woo, fellow and distinguished inventor at Rambus. “One of them is architectures. We have to think about what are the right ways to construct chips so they’re really targeted more toward the actual algorithms. We’ve been seeing that happen for the last four or five years. People have implemented some really neat architectures — things like systolic arrays and more targeted implementations. There are some other ones, too. We certainly know that memory systems are very, very important in the overall energy consumption. One of the things that has to happen is we have to work on making memory accesses more energy-efficient. Utilizing the PHY more effectively is an important piece. SoCs themselves are spending 25% to 40% of their power budget just on PHYs, and then the act of moving data back and forth between and SoC and a PHY — about two thirds of power being used is really just in the movement of the data. And that’s just for HBM2. For GDDR, even more of the power is spent in moving the data because it’s a higher data rate. For an equivalent bandwidth, it’s taking more power just because it’s a much higher speed signal.”

Fig. 2: Breakdown of data movement costs. Source: Rambus
Network optimization
Another place where this kind of approach is being utilized is network configuration and optimization. Unlike in the past, when a computer or smart phone could tap into any of a number of standards-based protocols and networks, the edge is focused on application-specific optimizations and unique implementations. Every component in the data flow needs to be optimized, sometimes across different systems that are connected together.
This is causing headaches for users, who have to integrate edge systems, as well as for vendors looking to sell a horizontal technology that can work across many vertical markets. And it is opening the door for more intelligent devices and components that can configure themselves on a network or in a package — as well as for configurable devices that can adapt to changes in algorithms used for those markets.
“It’s going to start out as software-defined hardware, but it’s going to evolve into a self-healing, self-orchestrating device that can be AI-enabled,” said Kartik Srinivasan, director of data center marketing at Xilinx. “It can say, ‘I’m going to do this level of processing for specific traffic flows,’ and do a multitude of offloads depending upon what AI is needed.”
AI/ML is proving to be very good at understanding how to prioritize and partition data based upon patterns of behavior and probabilities for where it can be best utilized. Not all data needs to be acted upon immediately, and much of it can be trashed locally.
“We’re starting to view machine learning as an optimization problem,” said Anoop Saha, senior manager for strategy and business development at Siemens EDA. “Machine learning historically has been used for pattern recognition, whether it’s supervised or unsupervised learning or reinforcement learning. The idea is that you recognize some pattern from the data that you have, and then use that to classify things to make predictions or do a cat-versus-dog identification. There are other use cases, though, such as a smart NIC card, where you didn’t find the network topology identifying how you maximize your SDN (software defined networking) network. These are not pure pattern-recognition problems, and they are very interesting for the broader industry. People are starting to use this for a variety of tasks.”
While the implementations are highly specific, general concepts are starting to come into focus across multiple markets. “It differs somewhat depending on the market segment that you’re in,” said Geoff Tate, CEO of Flex Logix. “We’re working at what we’re calling the enterprise edge for medical imaging and things like that. Our customers need high throughput, high accuracy, low cost, and low power. So you really have to have an architecture that’s better than GPUs, and we benchmarked ours at 3 to 10 times better. We do that with finer granularity, and rather than having a big matrix multiplier, we have our one-dimensional tensor processors. Those are modular, so we can combine them in different ways to do different convolution and matrix applications. That also requires a programmable interconnect, which we’ve developed. And the last thing we do is have our compute very close to memory, which minimizes latency and power. All of the computation takes place in SRAM, and then the DRAM is used for storing weights.”
AI on the edge
This modular and programmable kind of approach is often hidden in many of these designs, but the emphasis on flexibility in design and implementation is critical. More sensors, a flood of data, and a slowdown in the benefits of scaling, have forced chipmakers to pivot to more complex architectures that can drive down latency and power while boosting performance.
This is particularly true on the edge, where some of the devices are based on batteries, and in on-premises and near-premises data centers where speed is the critical factor. Solutions tend to be highly customized, heterogeneous, and often involve multiple chips in a package. So instead of a hyperscale cloud, where everything is located in one or more giant data centers, there are layers of processing based upon how quickly data needs to be acted upon and how much data needs to be processed.
The result is a massively complex data partitioning problem, because now that data has to be intelligently parsed between different servers and even between different systems. “We definitely see that trend, especially with more edge nodes on the way,” said Sandeep Krishnegowda, senior director of marketing and applications for memory solutions at Infineon. “When there’s more data coming in, you have to partition what you’re trying to accelerate. You don’t want to just send raw bits of information all the way to the cloud. It needs to be meaningful data. At the same time, you want real-time controller on the edge to actually make the inference decisions right there. All of this definitely has highlighted changes to architecture, making it more efficient at managing your traffic. But most importantly, a lot of this comes back to data and how you manage the data. And invariably a lot of that goes back to your memory and the subsystem of memory architectures.”
In addition, this becomes a routing problem because everything is connected and data is flowing back and forth.
“If you’re doing a data center chip, you’re designing at the reticle limit,” said Frank Schirrmeister, senior group director for solution marketing at Cadence. “You have an accelerator in there, different thermal aspects, and 3D-IC issues. When you move down to the wearable, you’re still dealing with equally relevant thermal power levels, and in a car you have an AI component. So this is going in all directions, and it needs a holistic approach. You need to optimize the low-power/thermal/energy activities regardless of where you are at the edge, and people will need to adapt systems for their workloads. Then it comes down to how you put these things together.”
That adds yet another level of complexity. “Initially it was, ‘I need the highest density SRAM I can get so that I can fit as many activations and weights on chip as possible,'” said Ron Lowman, strategic marketing manager for IP at Synopsys. “Other companies were saying they needed it to be as low power as possible. We had those types of solutions before, but we saw a lot of new requests specifically around AI. And then they moved to the next step where they’d say, ‘I need some customizations beyond the highest density or lowest leakage,’ because they’re combining them with specialized processing components such as memory and compute-type technologies. So there are building blocks, like primitive math blocks, DSP processors, RISC processors, and then a special neural network engine. All of those components make up the processing solution, which includes scalar, vector, and matrix multiplication, and memory architectures that are connected to it. When we first did these processors, it was assumed that you would have some sort of external memory interface, most likely LPDDR or DDR, and so a lot of systems were built that way around those assumptions. But there are unique architectures out there with high-bandwidth memories, and that changes how loads and stores are taken from those external memory interfaces and the sizes of those. Then the customer adds their special sauce. That will continue to grow as more niches are found.”
Those niches will increase the demand for more types of hardware, but they also will drive demand for continued expansion of these base-level technologies that can be form-fitted to a particular use case.
“Our FPGAs are littered with memory across the entire device, so you can localize memory directly to the accelerator, which can be a deep learning processing unit,” said Jayson Bethurem, product line manager at Xilinx. “And because the architecture is not fixed, it can be adapted to different characterizations, and classification topologies, with CNNs and other things like that. That’s where most of the application growth is, and we see people wanting to classify something before they react to it.”
AI’s limits in end devices
AI itself is not a fixed technology. Different pieces of an AI solution are in motion as the technology adapts and optimizes, so processing results typically come in the form of distributions and probabilities of acceptability.
That makes it particularly difficult to define the precision and reliability of AI, because the metrics for each implementation and use case are different, and it’s one reason why the chip industry is treading carefully with this technology. For example, consider AI/ML in a car with assisted driving. The data inputs and decisions need to be made in real time, but the AI system needs to be able to weight the value of that data, which may be different from how another vehicle weights that data. Assuming the two vehicles don’t ever interact, that’s not a problem. But if they’re sharing information, the result can be very different.
“That’s somewhat of an open problem,” said Rob Aitken, fellow and director of technology for Arm’s Research and Development Group. “If you have a system with a given accuracy and another with a different accuracy, then cumulatively their accuracy depends on how independent they are from each other. But it also depends on what mechanism you use to combine the two. This seems to be reasonably well understood in things like image recognition, but it’s harder when you’re looking at an automotive application where you’ve got some radar data and some camera data. They’re effectively independent of one another, but their accuracies are dependent on external factors that you would have to know, in addition to everything else. So the radar may say, ‘This is a cat,’ but the camera says there’s nothing there. If it’s dark, then the radar is probably right. If it’s raining, maybe the radar is wrong, too. These external bits can come into play very, very quickly and start to overwhelm any rule of thumb.”
All of those interactions need to be understood in detail. “A lot of designs in automotive are highly configurable, and they’re configurable even on the fly based on the data they’re getting from sensors,” said Simon Rance, head of marketing at ClioSoft. “The data is going from those sensors back to processors. The sheer amount of data that’s running from the vehicle to the data center and back to the vehicle, all of that has to be traced. If something goes wrong, they’ve got to trace it and figure out what the root cause is. That’s where there’s a need to be filled.”
Another problem is knowing what is relevant data and what is not. “When you’re shifting AI to the edge, you shift something like a model, which means that you already know what is the relevant part of the information and what is not,” said Dirk Mayer, department head for distributed data processing and control in Fraunhofer IIS’ Engineering of Adaptive Systems Division. “Even if you just do something like a low-pass filtering or high-pass filtering or averaging, you have something in mind that tells you, ‘Okay, this is relevant if you apply a low-pass filter, or you just need data up to 100 Hz or so.'”
The challenge is being able to leverage that across multiple implementations of AI. “Even if you look at something basic, like a milling machine, the process is the same but the machines may be totally different,” Mayer said. “The process materials are different, the materials being milled are different, the process speed is different, and so on. It’s quite hard to invent artificial intelligence that adapts itself from one machine to another. You always need a retraining stage and time to collect new data. This will be a very interesting research area to invent something like building blocks for AI, where the algorithm is widely accepted in the industry and you can move it from this machine to that machine and it’s pre-trained. So you add domain expertise, some basic process parameters, and you can parameterize your algorithm so that it learns faster.”
Conclusion
That is not where the chip industry is today, however. AI and its sub-groups, machine learning and deep learning, add unique capabilities to an industry that was built on volume and mass reproducibility. While AI has been proven to be effective for certain things, such as optimizing data traffic and partitioning based upon use patterns, it has a long way to go before it can make much bigger decisions with predictable outcomes.
The early results of power reduction and performance improvements are encouraging. But they also need to be set in the context of a much broader set of systems, the rapid evolution of multiple market segments, and different approaches such as heterogeneous integration, domain-specific designs, and the limitations of data sharing across the supply chain.
Related
Putting Limits On What AI Systems Can Do
Developing these systems is just part of the challenge. Making sure they only do what they’re supposed to do may be even harder.
Hidden Costs In Faster, Low-Power AI Systems
Tradeoffs in AI/ML designs can affect everything from aging to reliability, but not always in predictable ways.
Tradeoffs To Improve Performance, Lower Power
Customized designs are becoming the norm, but making them work isn’t so simple.

 |
 |
 |
|
 |
 |
 |
|
 |
Leave a Reply